Overview
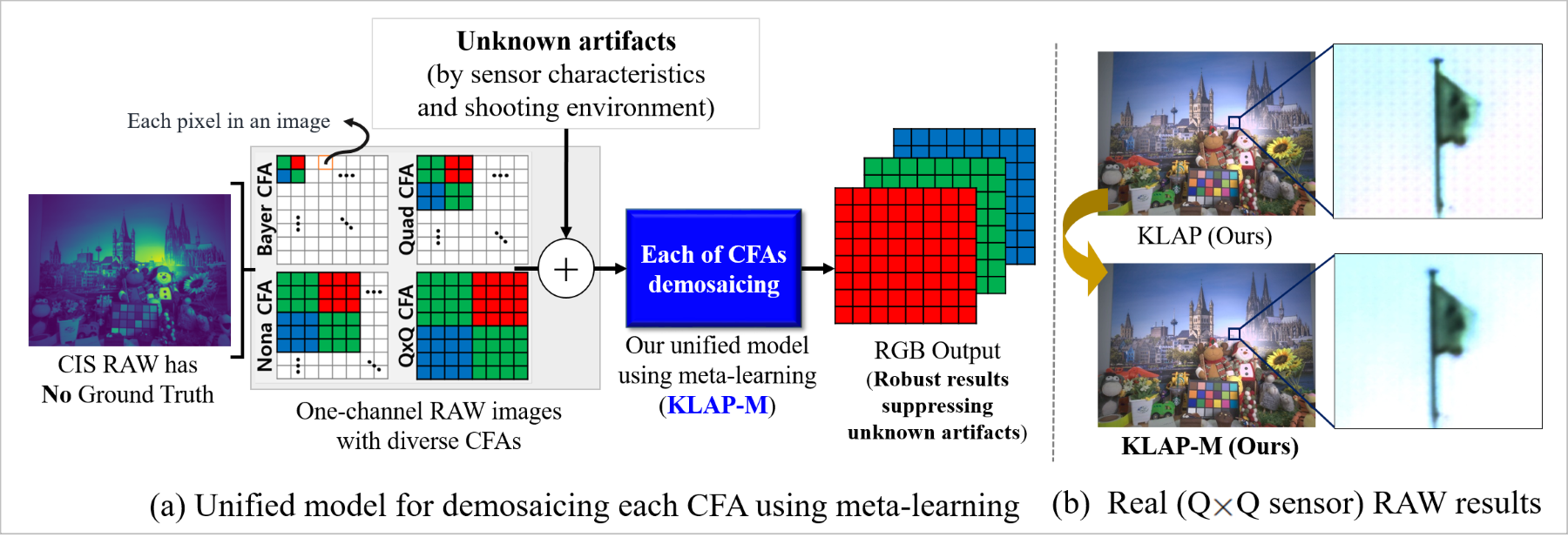
(a) Overview of our unified model (UM) for demosaicing all the Bayer and non-Bayer CFAs, called the Knowledge Learning-based demosaicing model for Adaptive Patterns using Meta-test learning (KLAP-M), even when ground truth is unavailable and unknown artifacts are present. (b) Comparing CIS RAW demosaicing results of KLAP (KLAP-M without meta-test learning) and KLAP-M (KLAP with meta-test learning).
Data Synthesis
Overview of our pipeline for synthesizing realistic RAW images, specifically for QxQ patterns.
KLAP-M Architecture
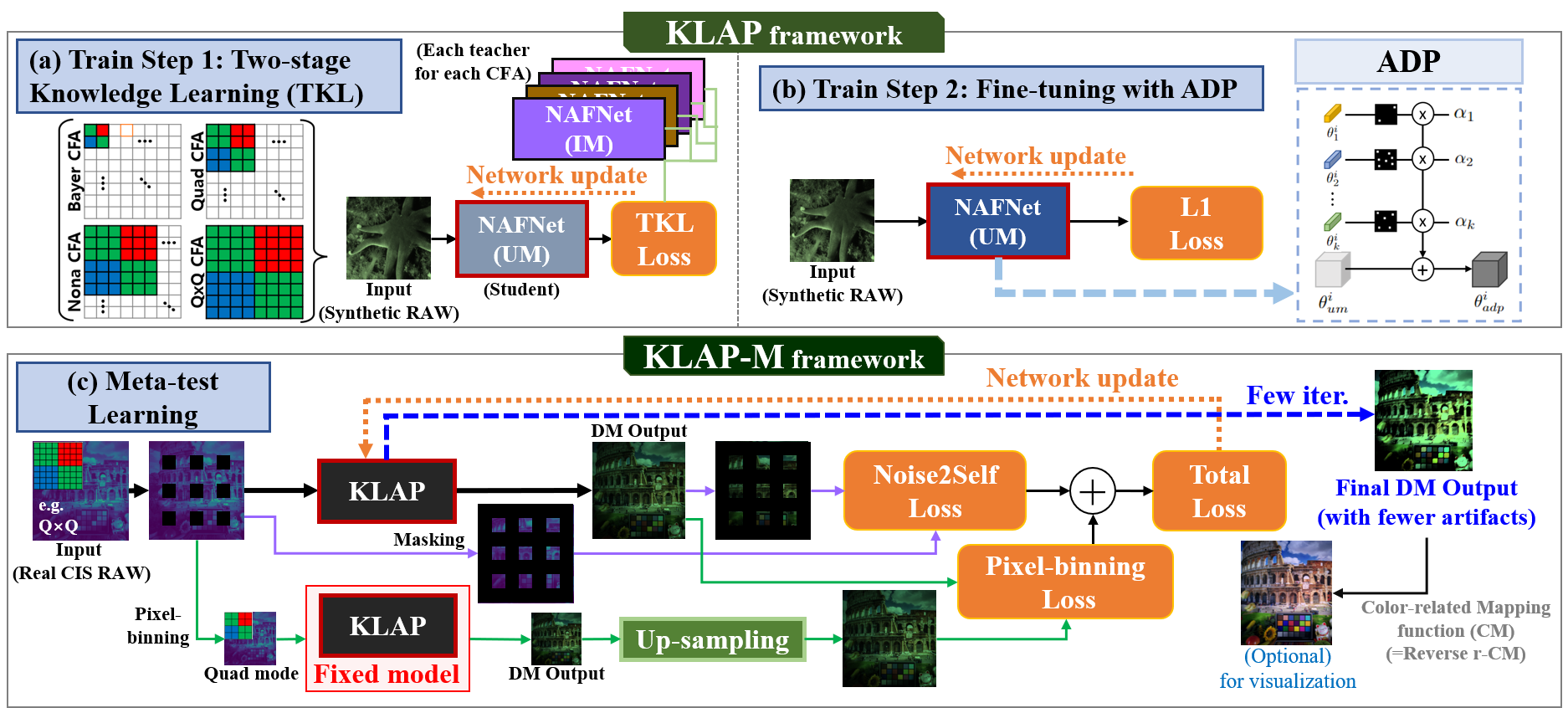
Overview of our proposed unified DM model, Knowledge Learning-based demosaicing model for Adaptive Pattern (KLAP) and KLAP with Meta-test learning (KLAP-M). KLAP consists of 2 steps: (a) two-stage knowledge learning (TKL) for training baselines, (b) fine-tuning using Adaptive Discriminant filters for each specific CFA Pattern (ADP). (c) KLAP-M employs meta-learning to reduce unknown artifacts in real RAW images during inference
Experiments
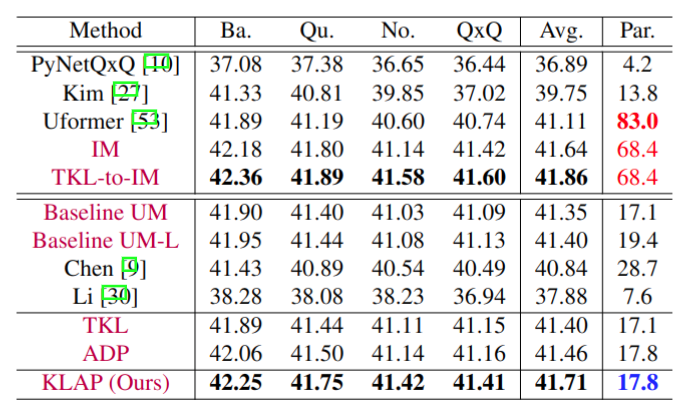
Ablation studies and quantitative performance comparison (PynetQxQ, Kim, Uformer, Chen and Li) for KLAP (TKL+ADP) on DF2K-CIS test dataset. PyNetQxQ, Kim and Uformer are independent models, while Chen and Li are unified models. The methods highlighted in purple are based on NAFNet. Baseline-UM is a simple unified model. TKL refers to the TKL-applied Baseline UM, and ADP refers to the ADP-applied Baseline UM independently. TKL-to-IM refers to the fine-tuned IM using TKL. Avg. denotes mean of all CFA's PSNR (dB), and Par. denotes the required number of parameters (Million).
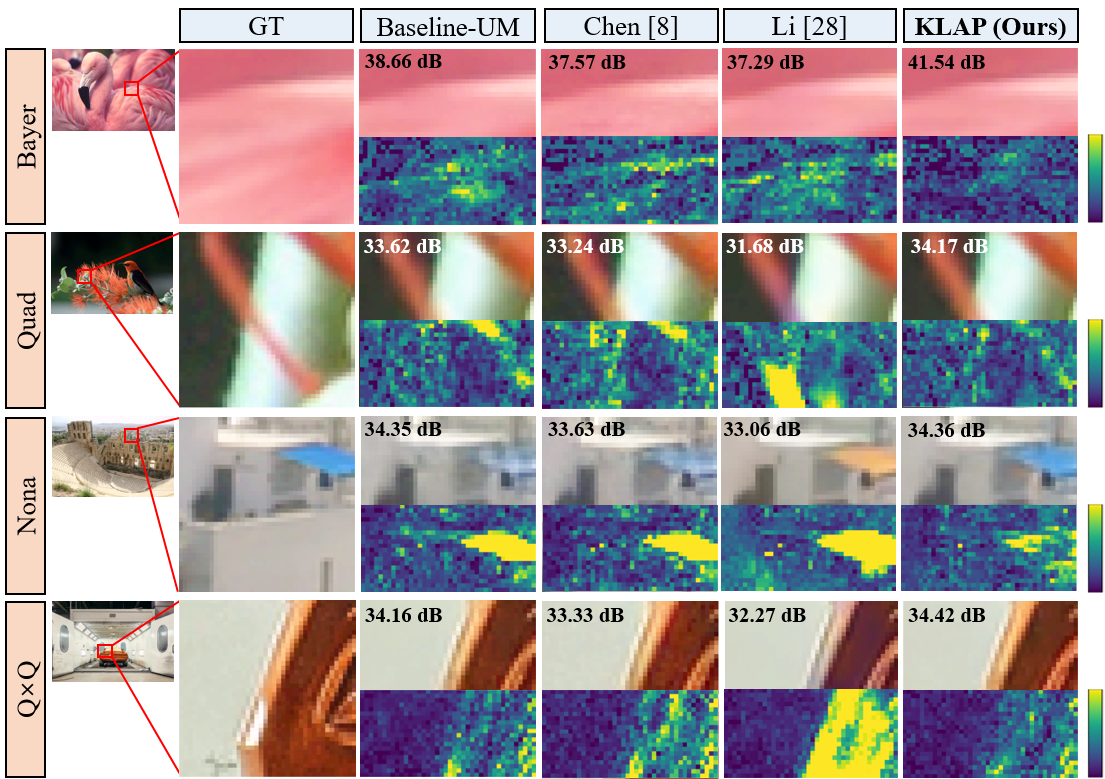
Comparison of demosaiced results top and their difference maps bottom on the synthetic RAW (DF2K-CIS) test set produced by different methods. The PSNR (dB) values displayed in the top-left corner are for the entire image. As shown, our proposed KLAP demonstrates the best performance. Note that CM is applied to the DM outputs for visualization.

Comparisons among different methods of robustness on DF2K-CIS with strong noise test dataset. The noise parameters used in the test are four times larger than the noise parameters used in the training. The number of meta-learning iterations in KLAP-M is set to 10, based on empirical determination through visualization of outputs in our experiments.

Qualitative DM results on the real CIS RAW. Note that KLAP with meta-test learning (KLAP-M) shows robust performance in real CIS RAW, despite of existence of sensor-generic unknown artifacts. Note that CM is applied to the DM outputs for visualization.

Additional inference images of CIS RAW, MIPI 2022 Quad remosaic challenge data using KLAP (trained by our synthetic dataset, DF2K-CIS) and KLAP-M. (a) demosaiced output images obtained using KLAP-M inference, and (b) the same images as in (b) after applying CM (Color-related Mapping function). As shown in the figures above, KLAP with meta-test learning (KLAP-M) shows robust performance in another real CIS RAW, MIPI 2022 Quad data, despite of existence of sensor-generic unknown artifacts.
BibTeX
@inproceedings{lee2023efficient,
title={Efficient Unified Demosaicing for Bayer and Non-Bayer Patterned Image Sensors},
author={Lee, Haechang and Park, Dongwon and Jeong, Wongi and Kim, Kijeong and Je, Hyunwoo and Ryu, Dongil and Chun, Se Young},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={12750--12759},
year={2023}
}